
こんにちは、小林です。
AI周辺の知識が全くなかった為、調べました。
調べて勉強した結果、ほんの少しだけ理解出来ました。
全て出来るだけ簡潔にまとめています(間違っていたらすみません&あまり深く書いてないのでその点ご了承ください)。
結論からいくと、
- 適時適応することが最も重要
- とりあえずAIという言葉はかなり広義で曖昧
目次
1. とりあえず図でまとめてみた
AIなどそれに関係する言葉は聞いたことがあるが、その意味や中身を理解していなかった...
為、大まかに図にまとめてみました。
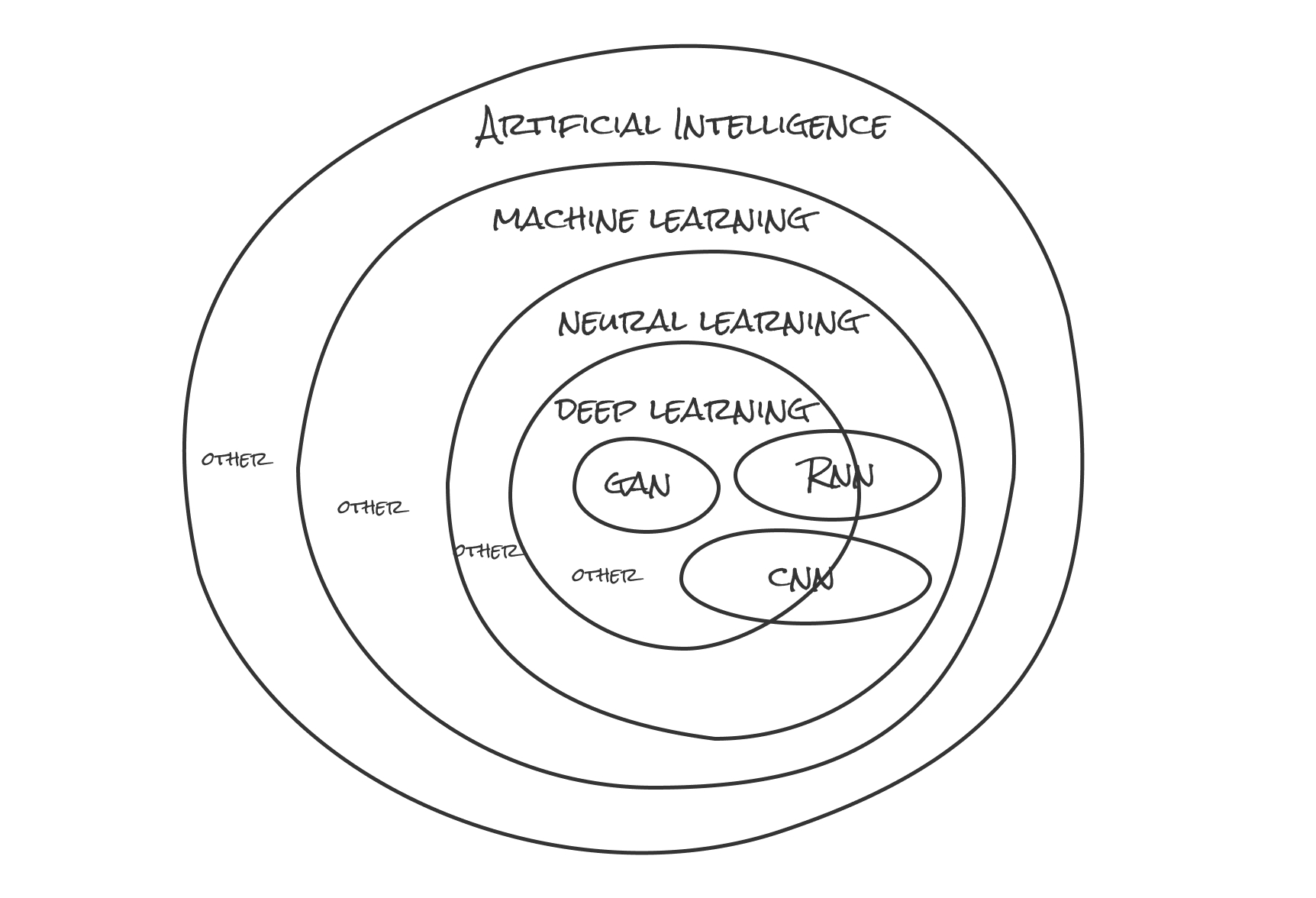
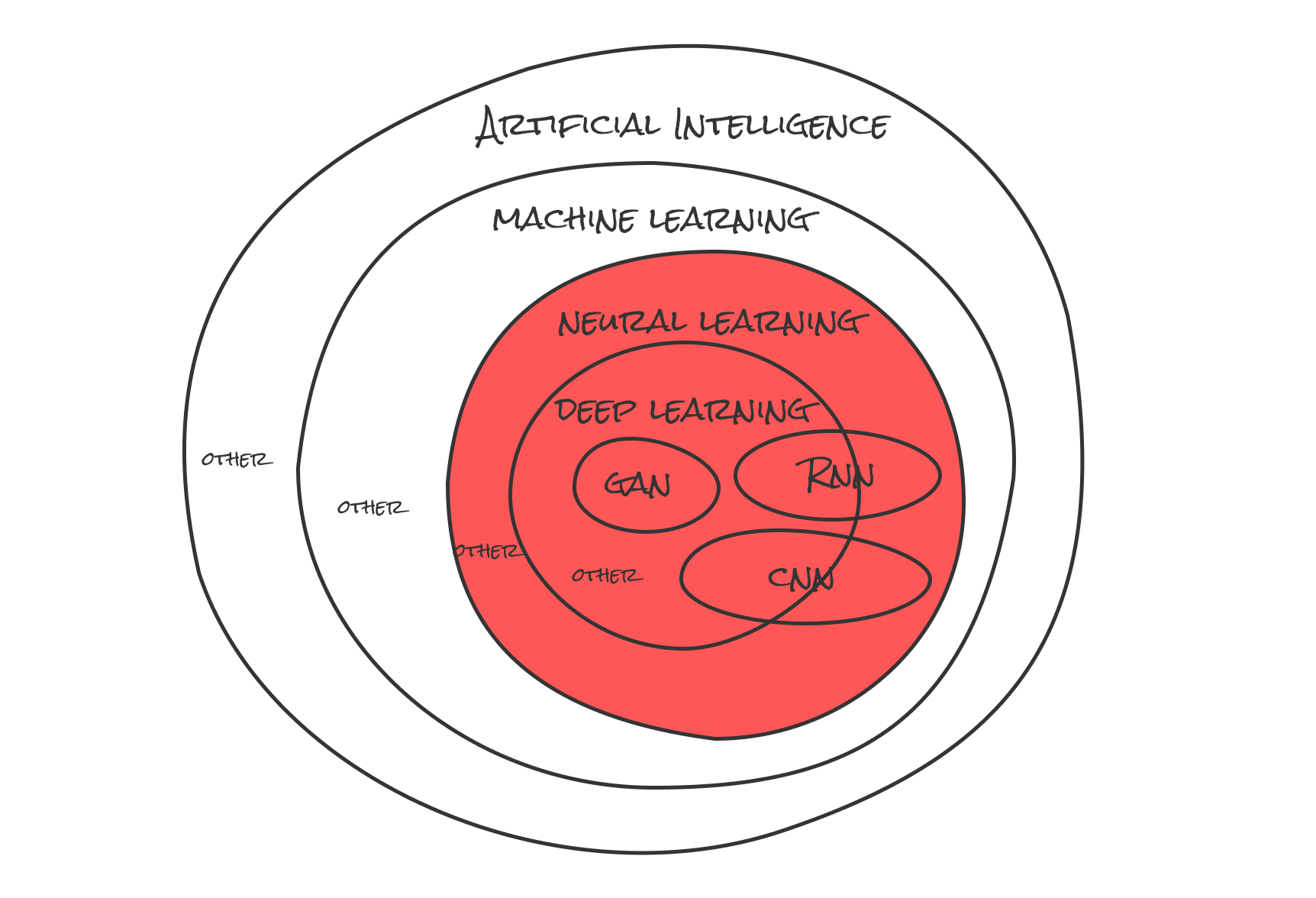
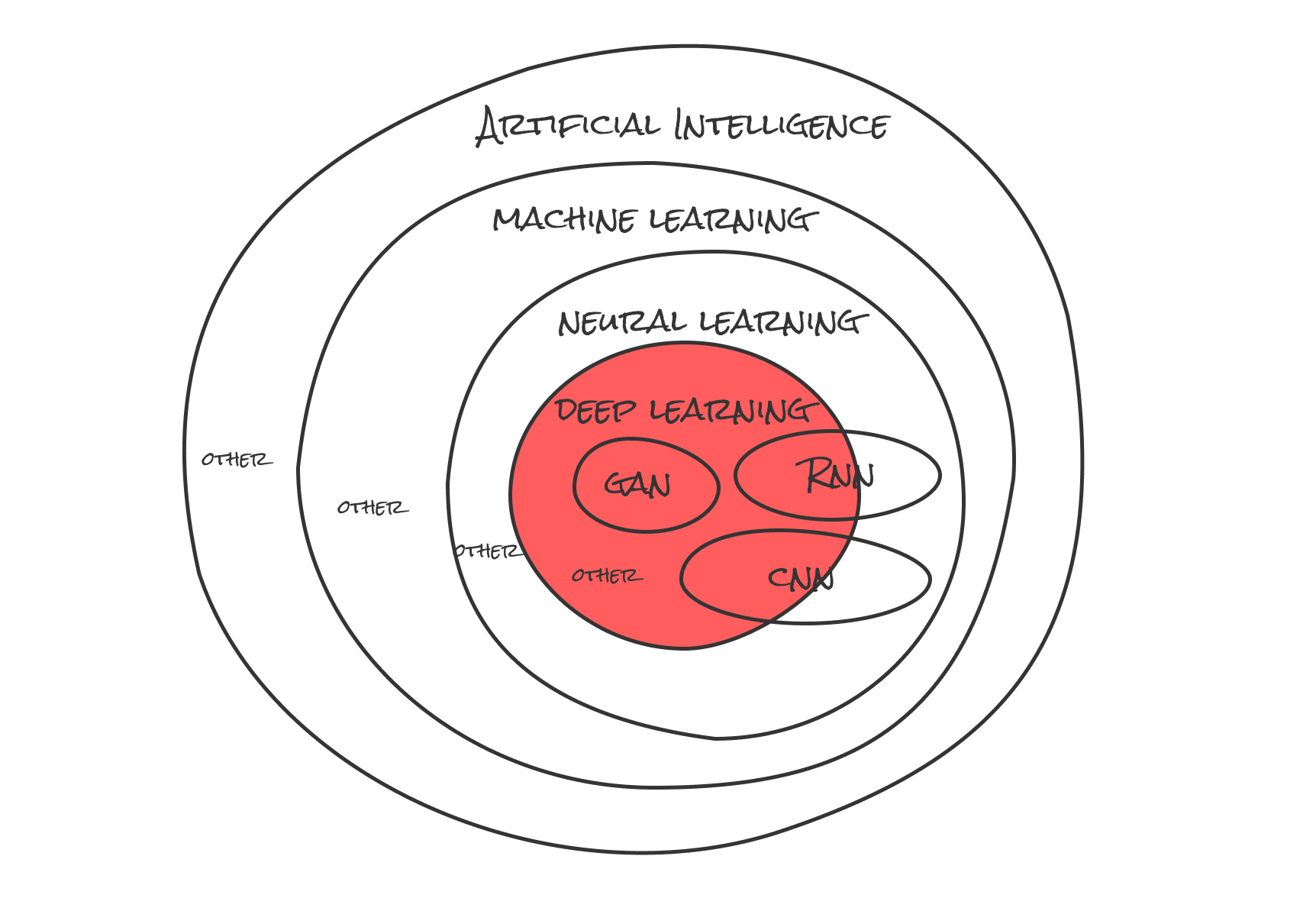
とりあえずこの図全体がAI(Artificial Intelligence)です。それの中になんとなく聞いたことがある言葉がAIの中に詰め込まれている...(後ほど説明)。
漠然と感じたのは、現在これらの言葉は一体どれくらい注目を集めているんだろうか...
ということでGoogle Trendsを使用し、検索数を調べてみました。
2. Google Trendsで調べてみた
とりあえず
- Machine Learning
- Deep Learning
で検索をかけてみました。(検索期間としては現在から1年前まで)
*ご存知だと思いますが、Google Trendsの結果の見方として
- 例えばスコアの100(Max):調査対象のキーワードが最もよく検索されている時点のスコア
ということを前提に置いておきます。
調べてみると、
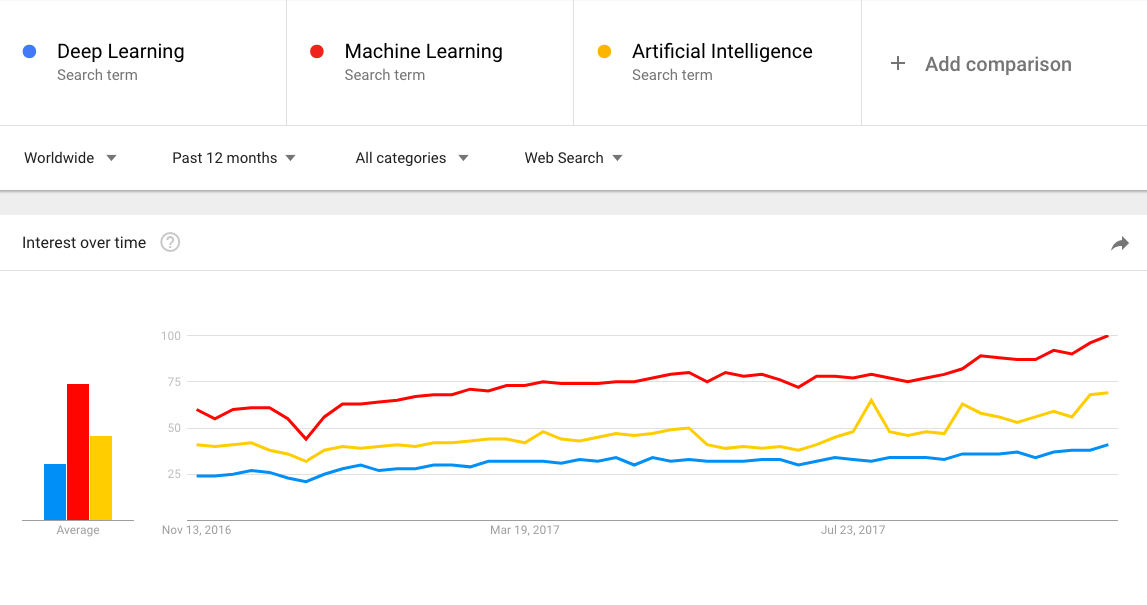
のように一番多く検索がかかっているのが
- Machine Learning
でした。これらは正式な名前でかけているので国や地域で検索順位に変動が出ると思います(日本語で"マシーンラーニング"のように検索する人もいるから)。
ちなみにここに
- AI
を入れるとこんな感じです。
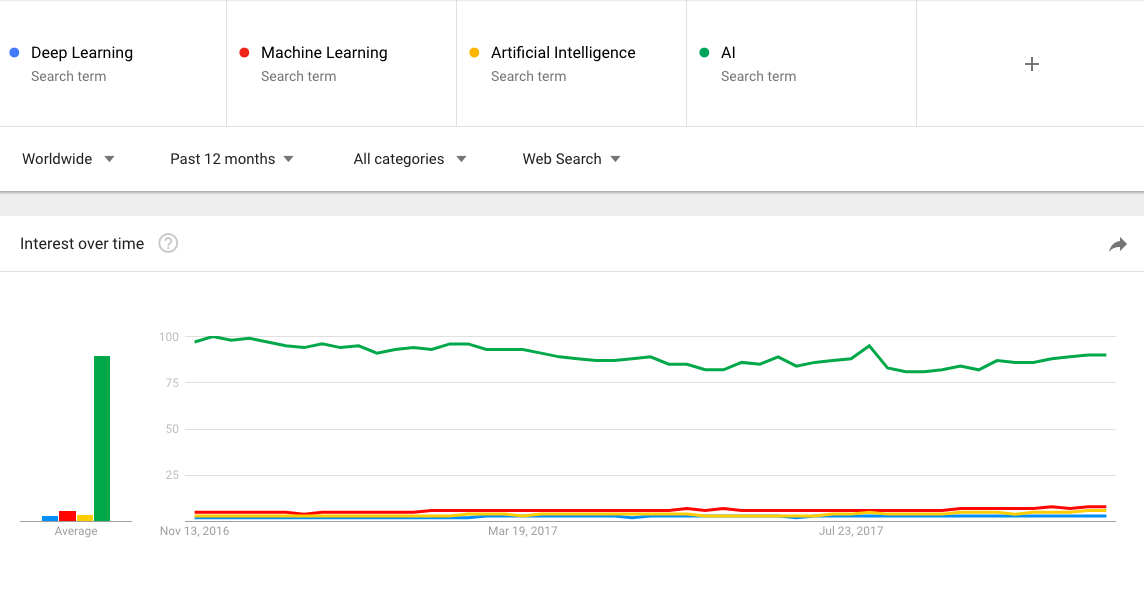
桁違い感がありますね(”AI”という言葉でもおそらくArtificial Intelligence以外の意味で検索している人もいるだろうが)。これだけだと検索実数も見えない上に凄さがよく分からないので、ついでに全然関係がないですが検索数が高そうな言葉も入れてみました。
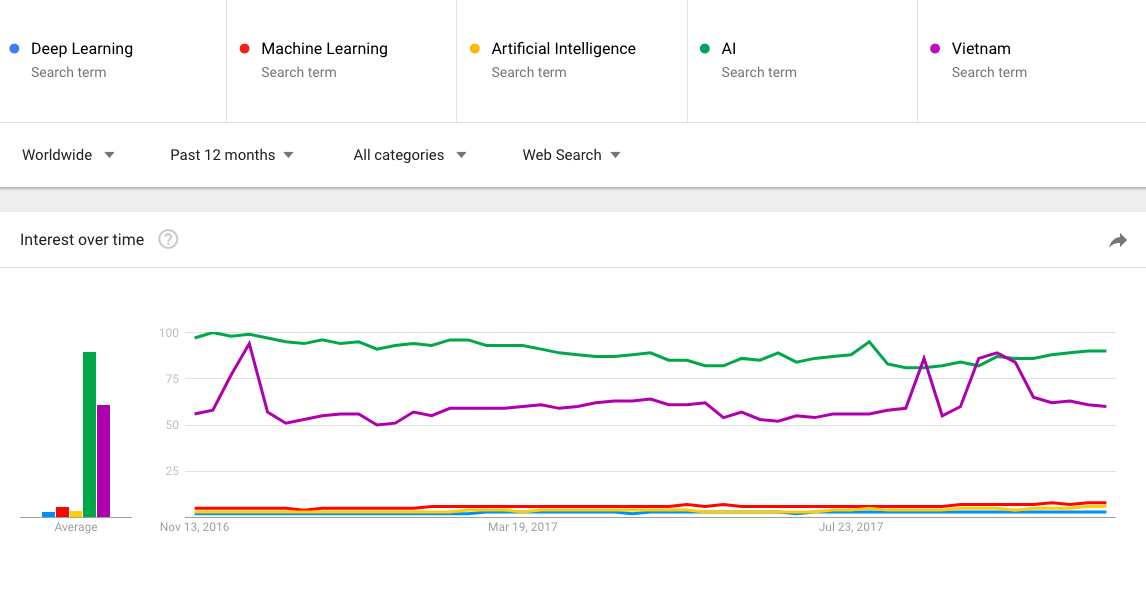
具体的には言いませんが、これで値の凄さになんとなく気づいた気がします(”AI”は国名を超えてしまう検索値=注目度が高い)。ここ1年間での統計ですが、気になっている人が相変わらず多いなと感じました。
早速これらの関係性や中身に迫っていきましょう。
3. AI(Artificial Intelligence)とは
よくAIが〜などの話を耳にしますが、そもそもAIって何となく理解してるけど具体的に何?と思っている人は少なくないと思います。色んな意味がありますが、一言で言うと”人工知能”というやつですね。
部分的にはここ(赤い部分)↓
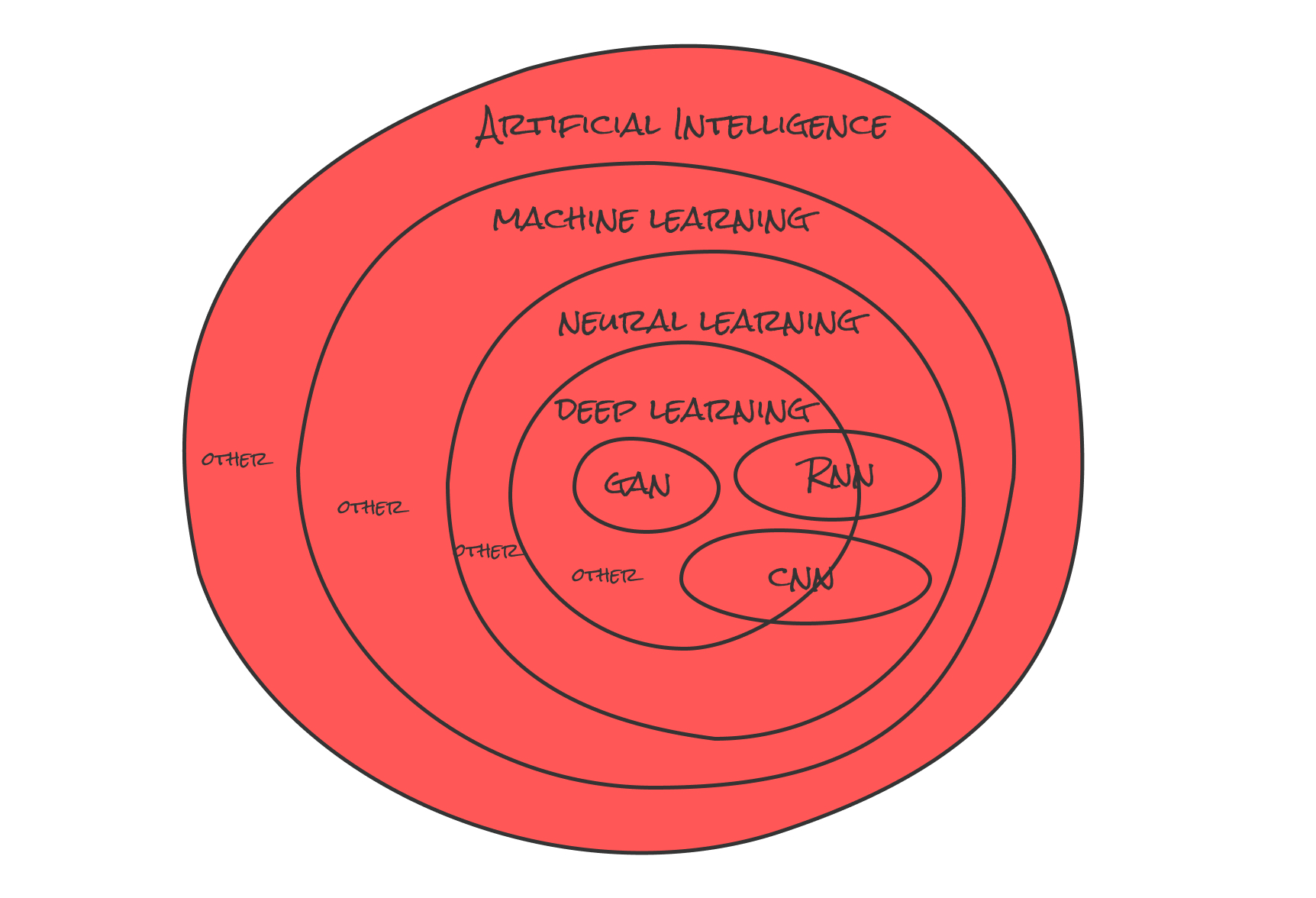
とりあえず広義な言葉と覚えておきます(ガチガチに定義付けをされていないみたいなので)。そもそも約1950年頃から人工知能の歴史があるようですね。AIの定義を個人的にまとめると、
知的な行動(人間の知能とは限らずに)を再現する(しようとする又は同等)技術が集まったもの(上記の図で言うとMachine LearningやDeep Learningのような)を人工知能と呼び、その考え方が広義の意味で人工知能(語弊があったらすみません)。
AIの大きな分類としては、
- 特化型人工知能(ANI:Artificial Narrow Intelligence)
の2つと言われていますね。これではよく分からないのでもう少し詳しく説明すると、
- 特化型人工知能(ANI:Artificial Narrow Intelligence):個別の領域においてまるで人間の様に思考するAI(画像認識や音声認識等)
更に短く簡単に言うと
- 特化型人工知能(ANI:Artificial Narrow Intelligence):弱いAI or 狭いAI
のような感じですね。多くの論文や記事で強いAIや弱いAI等の表現で書かれていることが多いです。上を見ればわかりますが、主に現在使用されているものが特化型人工知能です(弱いAI)。そしてどんどん我々の身に迫っているものが汎用型人工知能(強いAI)です。
AIに関してふんわり理解したところで更に中身を掘り下げていきます。
4. ML(Machine Learning)とは
Machine Learningとは(以下ML)
↓
与えられた情報を元に学習する
↓
それを元に自律的に法則やルールを見つけ出す手法やプログラム
のような感じですね。
部分的にはここ↓
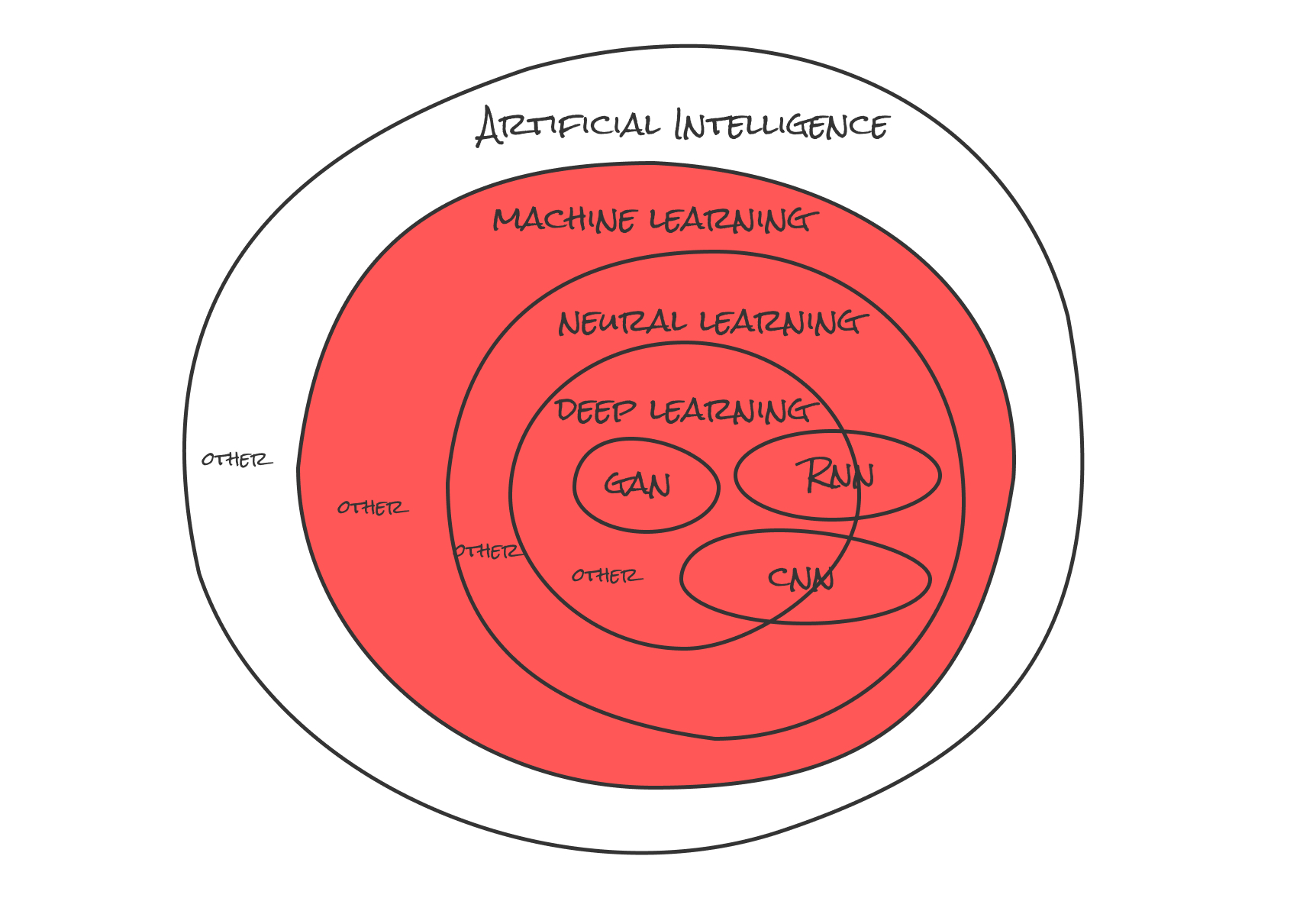
MLは主に4つのアルゴリズムに分類出来ます。
4.1. 教師有り学習(Supervised Learning)
教師有り学習とは一言で言うと、
”正解を教える”学習方法
です。例えば、こんな羅列した画像があるとします。

これらの文字を下図のように、文字1つ1つにラベル(これは〜です等)をつけていきます。

このラベルを人間がつけることによって機械は学習する、といった流れです(人間側がかなり労力を使う)。
主に回帰や分類という概念を持っています。以下簡易的な説明です。
回帰:データを入力すると、出力として数値を返す方法(予測)
それぞれ図にしてみました。
分類
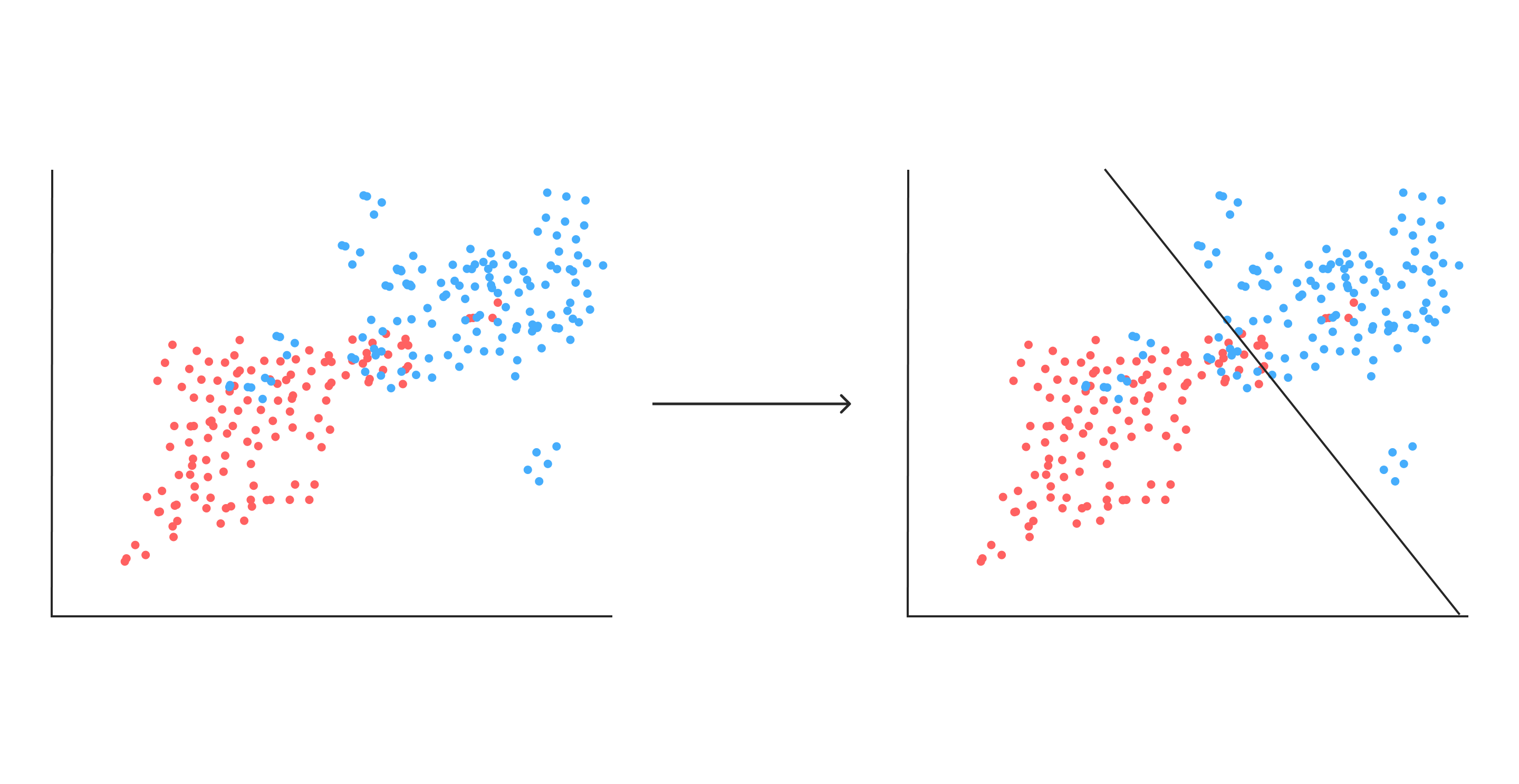
過去の入力数値を元に、新たに与えられたデータをグループに仕分けする概念。
回帰

過去の入力数値から未来の数値を予測する概念(簡単に言うと”数値予測”)。
4.2. 教師無し学習(Unsupervised Learning)
これは教師有り学習の逆で、”正解を教えない(人間がラベルをつけない)”学習方法です。
根本的にデータの読み込ませ方が教師あり学習と異なります(まさに後ほど紹介するDeep Learning)。
主に以下2つの概念を持っています。
クラスタリング
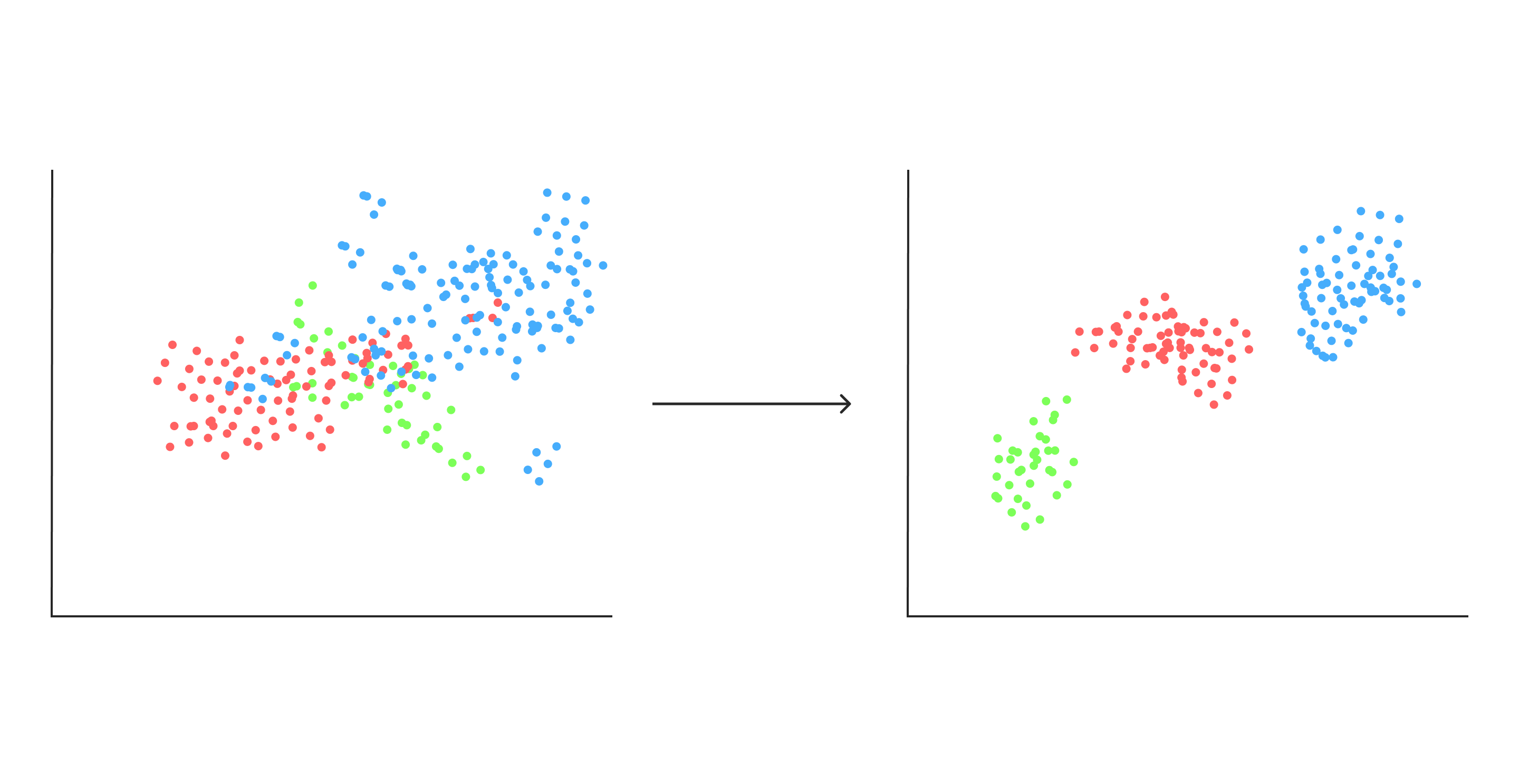
データを入力するとそのデータのグルーピング結果を返す方法。
外れ値検出(異常値検索)
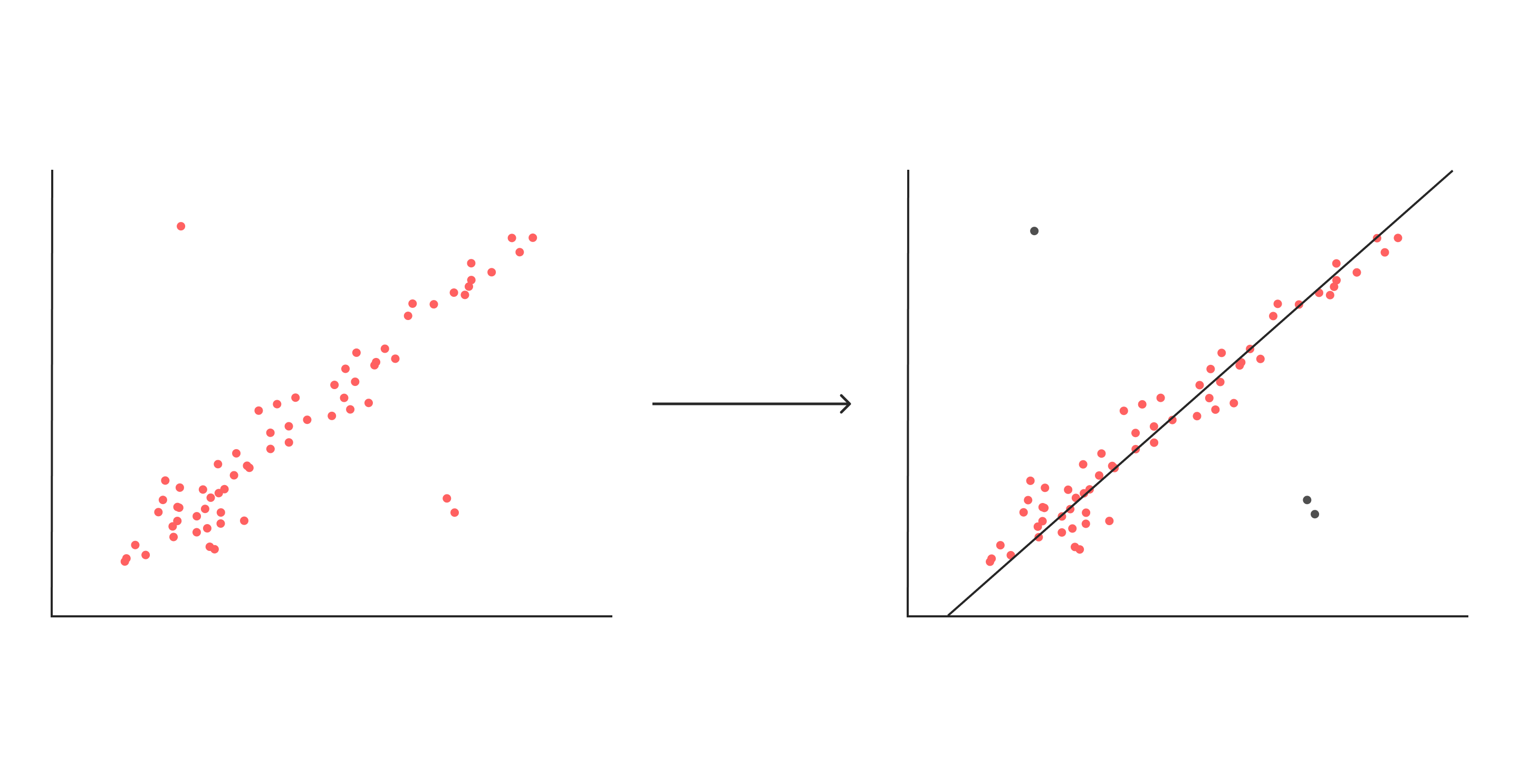
データから著しく外れたデータを異常値として検出する方法。
教師無し学習を更に簡単に言うと、
↓
膨大なデータから自動的に算出した特徴量から法則等を導き機械に学習させる方法
です。
ここで先ほどの教師あり学習の図と比べてみましょう
上図のような羅列した文字に関して

このように答えを与えないのが教師無し学習です。
機械がデータのパターンだけを見てデータの類似点を探らなくてはなりません。
4.3. 半教師有り学習(semi-supervised learning)
こちらはペアのデータ(ラベル付き)に加えて、予測対象が存在しない予測材料のみのデータ(ラベル無し)からも学習を行うことで、予測モデルの精度を向上させる手法です。簡単に言うと、ラベルが付いたデータと付いていないデータを両方を使用する学習法ですね。
画像で表すとこんな感じ↓

(半分ラベル付けるの面倒で4つしかつけていませんすみません)
なぜ半分だけかというと、
↓
半分だけにラベルをつけて残りはラベルなしで学習させる
↓
これをすることにより、人間による費用や労力を減すことができる
といった作業結果ではなく過程において大きなメリットがあります。
4.4. 報酬有り学習又は強化学習(Reinforcement Learning)
簡単に説明すると、
それが正解か不正解か人間でもわからない
↓
その為最終的な効果が最大化するように行動を学習する
のような感じです。つまり正解ではなく報酬を与える=最初は賢くないが報酬を与えるごとに賢くなります(その為たくさんのシュミレーションが行われる)。
与えられた正解の出力をそのまま学習すれば良いわけではなく、もっと広い意味での「価値」を最大化する行動を学習しなければならない、といった役割を持ちます。
例を出すと
- テトリスで高得点を叩き出す
- 株の長期保有
のように、長期的に見て最終的にメリットが得ることを目的とした学習法です(長期的にみて全てがうまくいくとは限らないが)。
全ての学習方法で読み込ませるデータが異なる=学習方法に違いがあり、適用できるシーンも変わってきます。これから説明するDLも同じように感じますが用途がはっきり分かれる為、どのシーンにおいてどの学習方法を選択するかが重要だと思います。
5. NN(Neural Network)とは
5.1. NNの概要
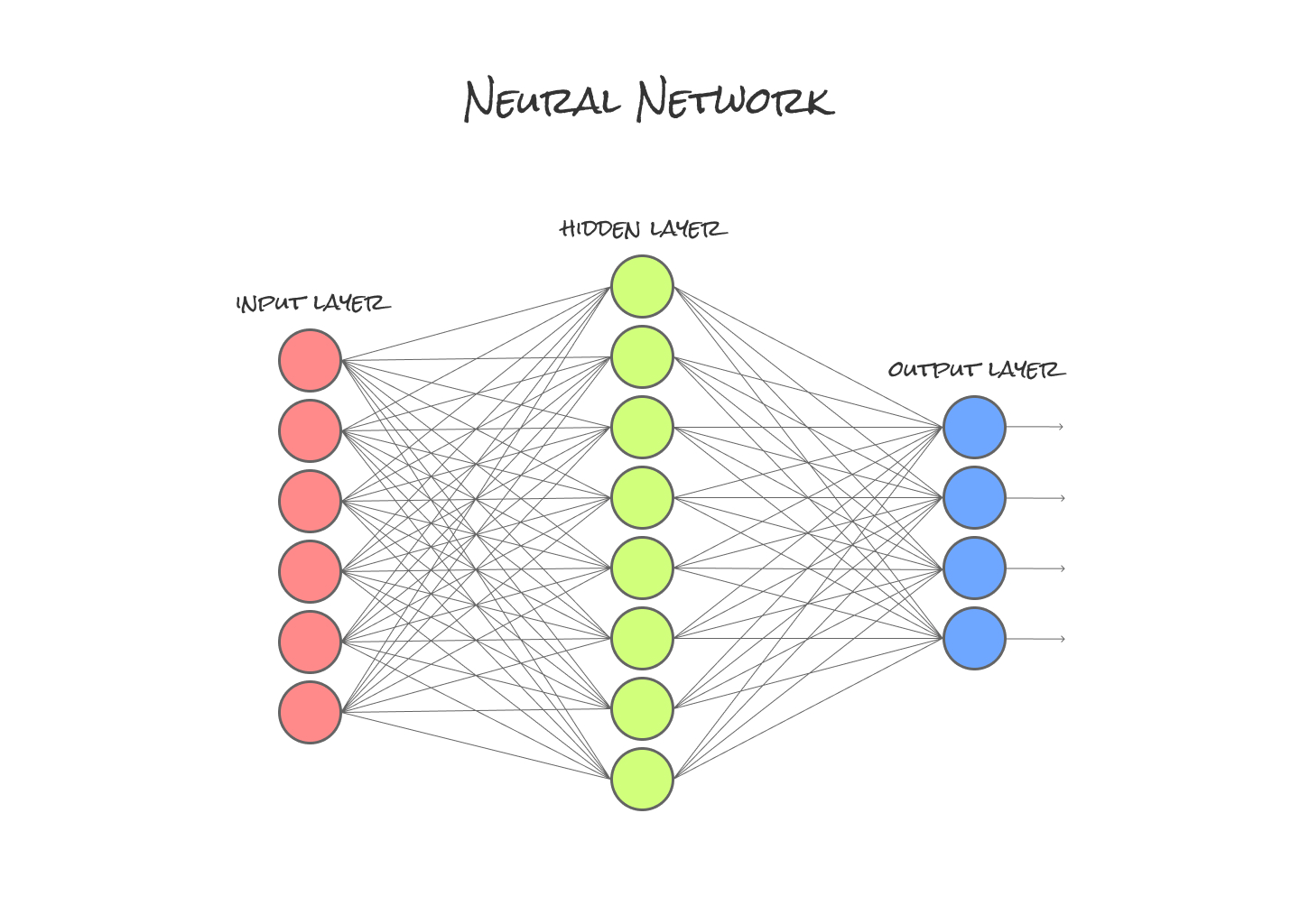
ニューラルネットワークとは、計算アルゴリズムのことです。
簡単にいうと、入力層、中間層、出力層という3層にニューロンというものを置きます。この3層を多層パーセプトロンと呼びます(単層パーセントプロンは2層のみの構造)。
ニューラルネットワークでは、識別して分類するために人間が提示したルールではなくある “特徴量” を算出し、それを使って分類していく流れですね。これらのプロセスで得た学習データの特徴を数値化します。
部分的にはここ↓
まずニューロンとNNの関係性を図に表してみました。
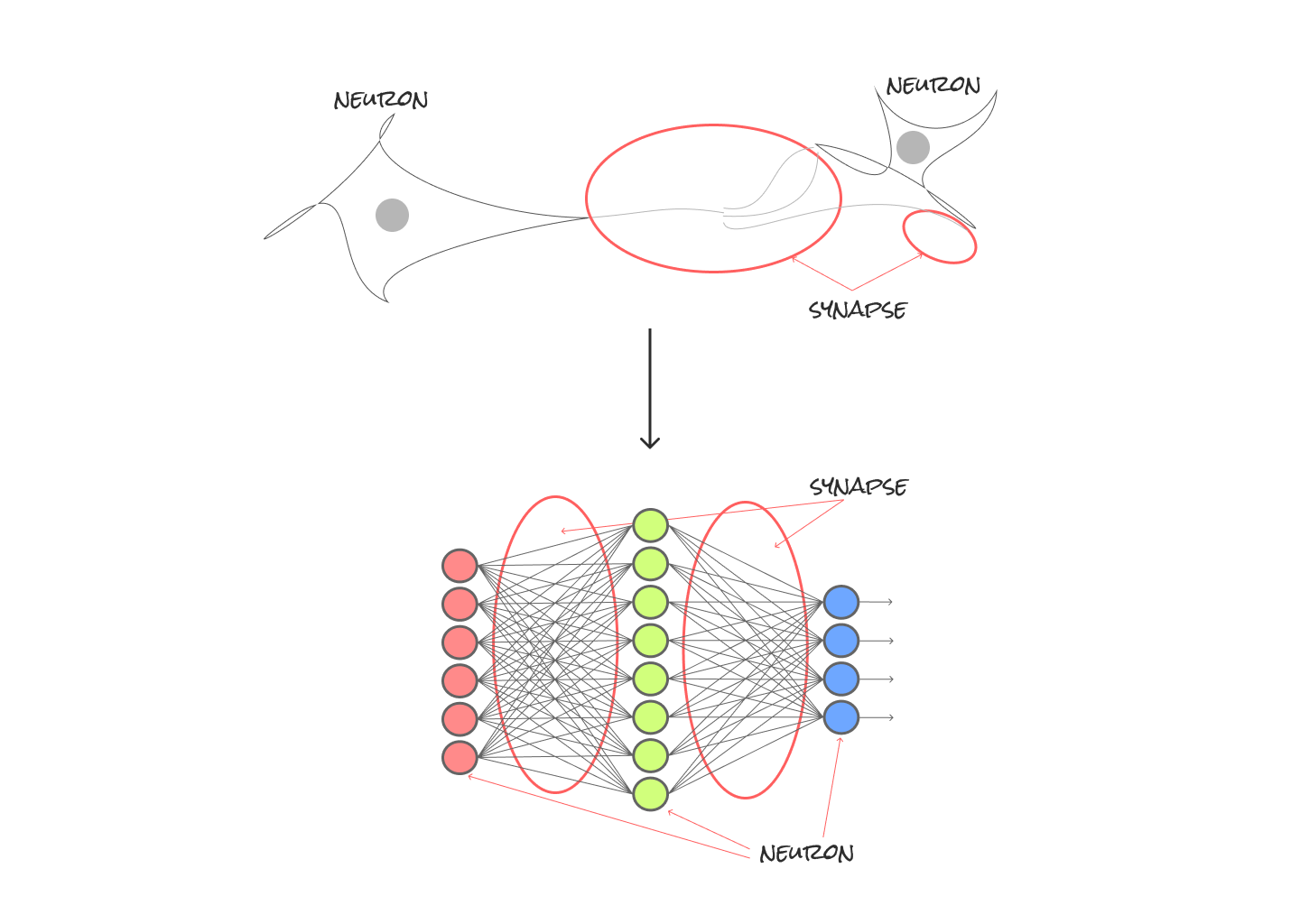
とりあえずニューロン(neuron)とシナプス(synapse)って何?って初めに感じたので、簡単に解説を入れておきます。
シナプス(synapse)=ニューロンと他のニューロンとの接合部分
上図は脳の中の神経細胞となるニューロンとNNの関係性をシミュレートしたものです(ニューロンがつながってできた層をディープに重ねたものが後ほど説明予定のDeep Learning)。
ではなぜ人口でニューロンを作るようになったのか?を時系列で説明すると、
↓
ニューロンは複数のシナプスからの入力信号を合わせて、ある値以上になると信号を次のニューロンに伝える
↓
従来はこれを物理的な電子回路でシミュレーションしていた
↓
最近はコンピュータ上のプログラムで作り、細胞の接続等の設定を自由に変えられるようになった(そしてそれを多層に接続して精度を上げたものがDL)
のように、確実に人間に近づいているなと感じます。
以上のNNの特徴をまとめると、これらの各層は複数の
ニューロン=ノード
が
シナプス=エッジ
で結ばれる構造です。
ノードの種類は先ほども述べた
- 隠れ層(中間層)
- 出力層
の3つに分類されます。隠れ層は複数種類のノード群から構成され、このノード群をユニット(よく見る層みたいな塊)と呼びます。このメリットとしては、
↓
ユニット内のノードを増やすことで1つのことをより正確に判別できるようになる。
ニューロンが理解できたところで、NNをとりあえず画像で表してみました。
次はアルゴリズムについて一部説明していきます。
5.2. NNの主なアルゴリズム
後ほど説明するDLの基盤となる主な2つを説明します。
5.2.1. 畳み込みニューラルネットワーク (CNN:Convolution Neural Networks)
これは畳み込み層(フィルタリングをして特徴量を取り出す層)とプーリング層(フィルタの結果から選択する層)を交互に繰り返すことでデータの特徴を抽出し、最後に全結合層で認識を行う手法です(後ほど画像でわかりやすく説明)。上記はConvNetとも呼ばれています。簡単に言うと、画像を複数のカテゴリに分類するよう学習をします。ここで一例を図にしました。
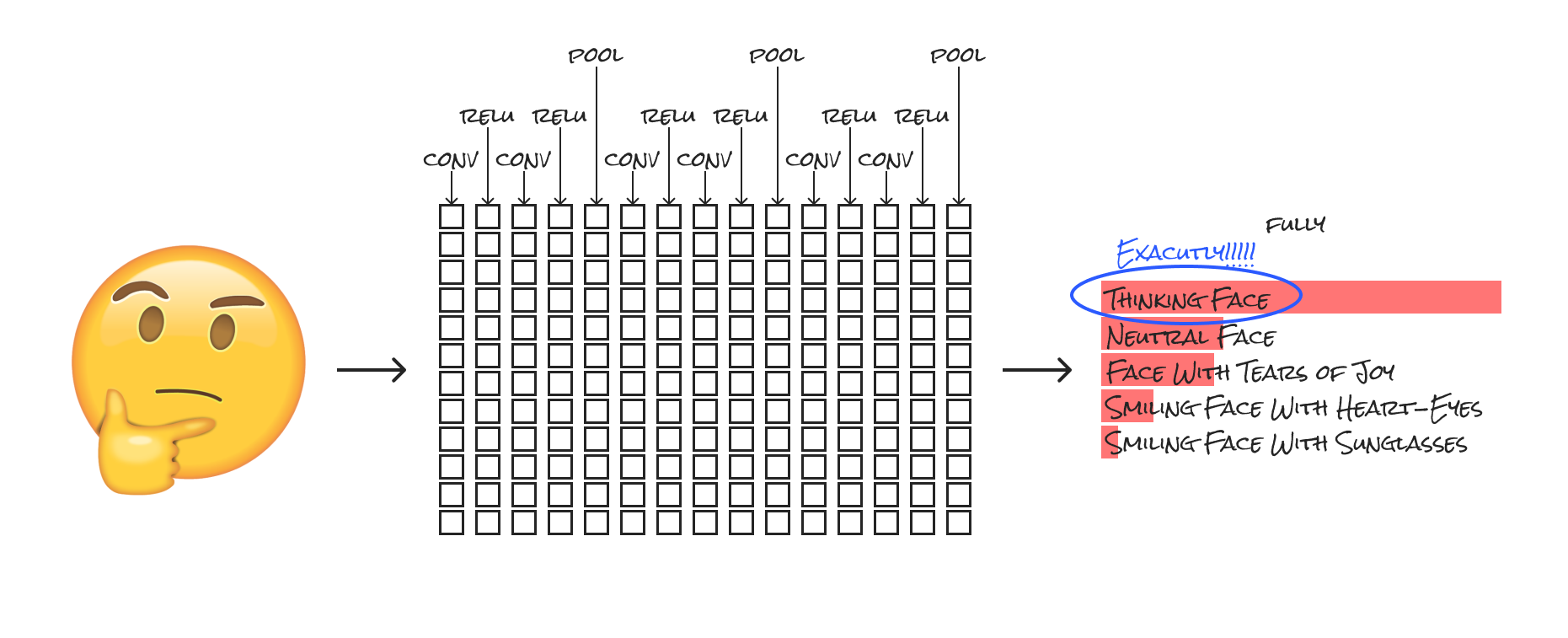
このように細かくカテゴリに分類していき結果を割り出すのですが、上図の説明をするとCNNにおけるレイヤーの種類は以下の4つがあります。
ReLU=活性化関数(画像では一例としてReLU)
POOL(Pooling Layer): レイヤの縮小を行い、扱いやすくするための層
Fully Connected Layer: 特徴量(同上)から、最終的な判定を行う層
これらのまとめると、
↓
活性化関数
↓
プーリング
が繰り返される流れです。
5.2.2. 再帰型ニューラルネットワーク(RNN:ecurrent Neural Networks)
中間層において、中間層の結果を自ら再度入力に用いることで、文脈理解を可能にする手法をCNNと呼びます。つまり中間層にループをもたせ1個前のデータを判断材料に使うことができる(入力データの記憶を保持させるため)メリットを持ちます。
ここで中間層同士で入力し合う画像を作ってみました。
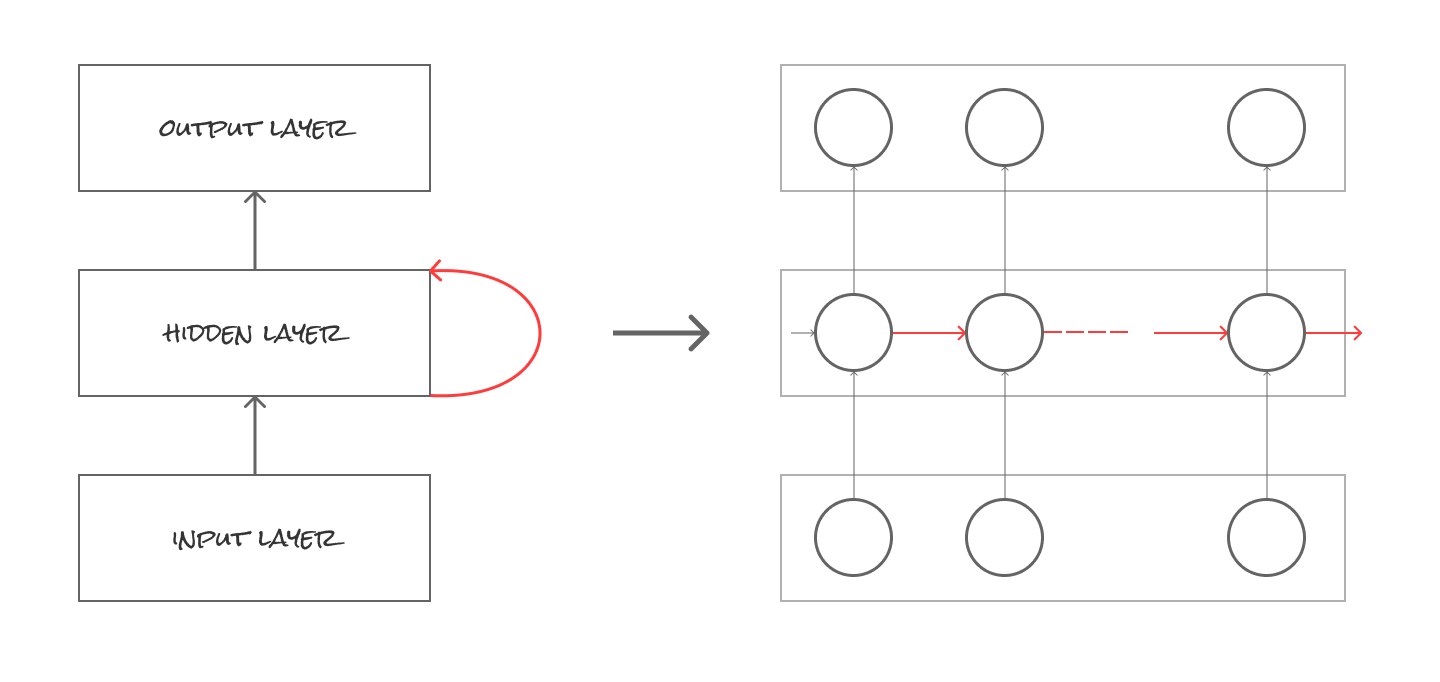
左側が大まかな図で左側が中間層にループをもたせ1個前のデータを判断材料として次のニューロンへ伝搬している図です。これは後ほど説明するDLのアルゴリズムにも大きく関わっています。
6. DL(Deep Learning)とは
ここから本題であるDeep Learningについて説明していきたいと思います(以下DL)。
6.1. 概要
一言で言うと、
機械学習の1種であるNeural Network(教師有り学習)の階層を深めたアルゴリズム
です。十分なデータ量があれば、人間の力なしに機械が自動的にデータから特徴を抽出してくれます。最初に説明した強いAIに最も近い存在の1つとされています。
部分的にはここ↓
とりあえず図に表してみました。
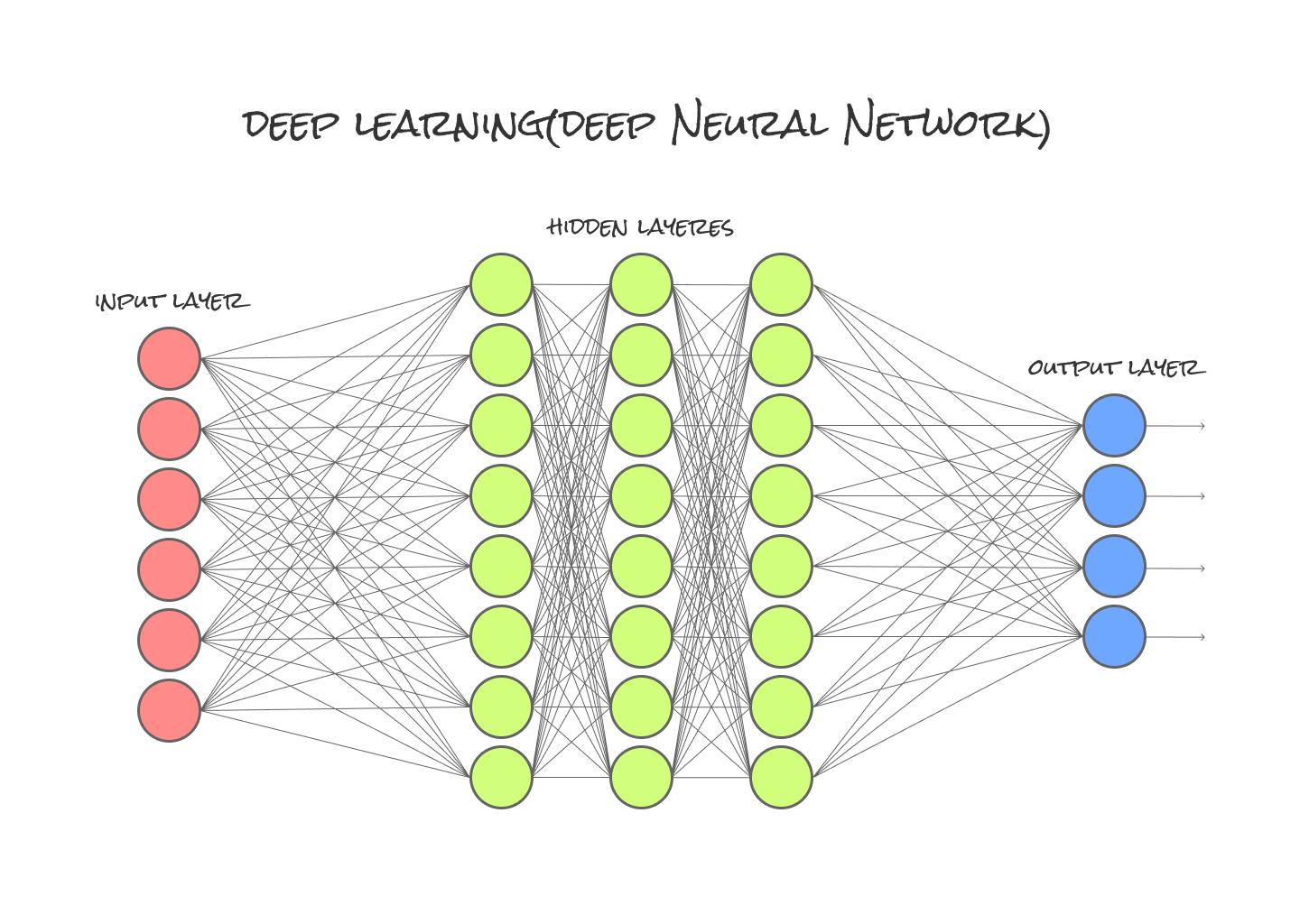
この隠れ層(hidden layer)は複数の層を持つことができ、特に深い隠れ層を持つものがDLと呼ばれています(中間層が2層以上になっている多層構造のNNをMLさせたものがDL)。
先ほどのNNと比べると
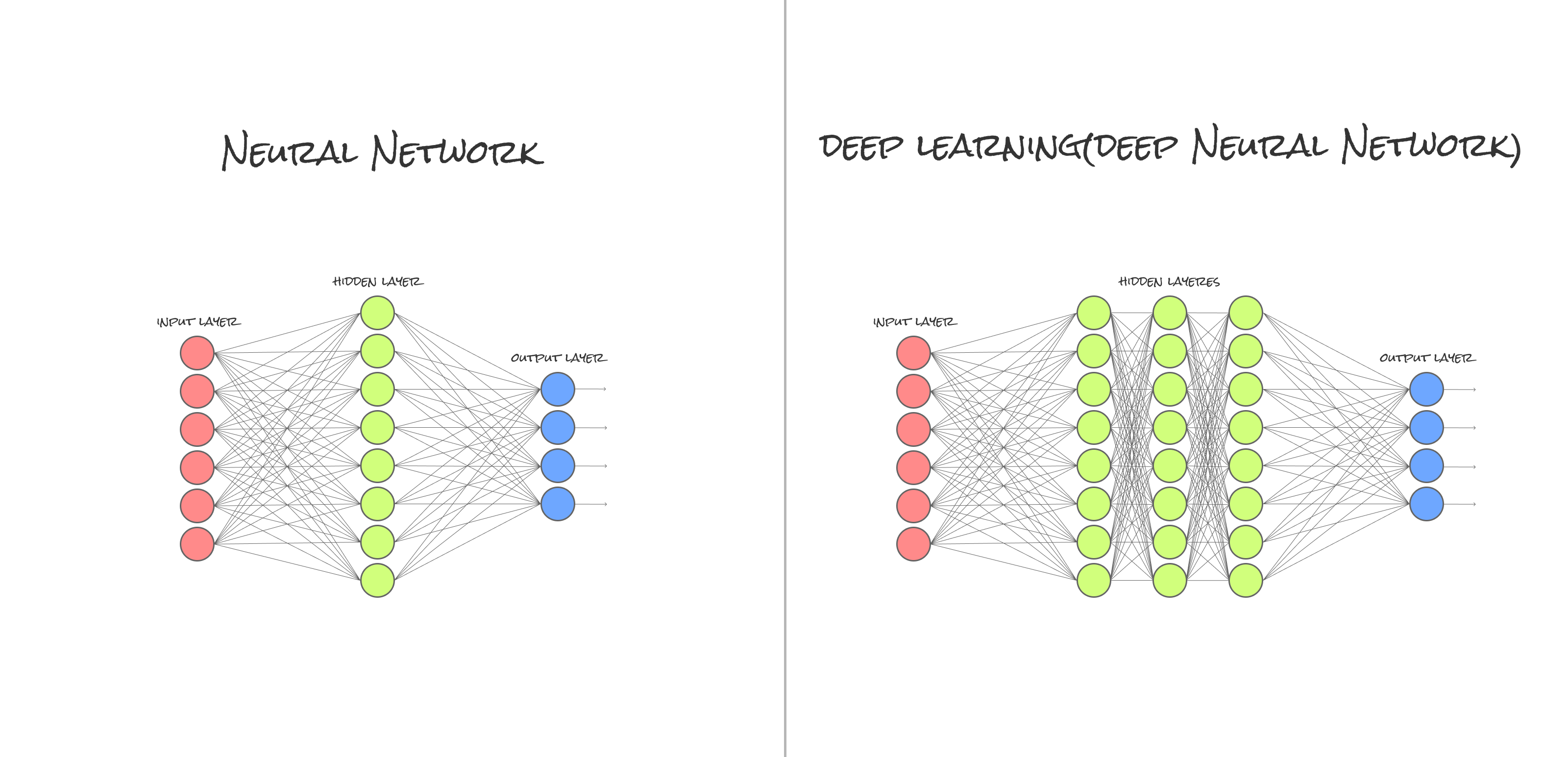
隠れ層(hidden layer)が異なりますね。この流れを可能にしたことで、
- 特徴量(後ほど説明)の精度や汎用性の向上
- 予測精度を向上
が可能となりました。従って、層やニューロンを増やすと分類能力が上がることが理解できますね。
ここでDeep Learningって何が具体的に凄いのか、まとめてみました。
↓
DLでは特徴量の自動獲得出来るようになった(=機械が自動でデータにどのような特徴があるのか取得し学習)
特微量が大きなポイントですね(後ほど説明)。またDLの特徴として、データの量が多ければ多いほど精度は上がります。逆にいうと、DLには
- 識別結果のチューニング(調べる)が難しい
という弱点あります。しかし大量のデータさえあれば、従来の機械学習などでは不可能だった複雑な扱いづらいデータも処理を行うことが可能になった点が大きな変化と感じます。
6.2. 事前学習(pre-training)とは
これは名の通り事前に学習をします。事前学習はアルゴリズムでもあるが、他のアルゴリズムと下記2つの違いは根底の計算をするということです(初期値を獲得するために)。つまり入力自体が教師データとなる為、DLにとってなくてはならない必要な要素です。
事前学習の「各層」の要素は主に
- 制限付きボルツマンマシン
- 積層オートエンコーダ
の二種類に分類されます。どちらも情報圧縮を行う事ができるNNですが、学習の過程が大きな違いです。上記2つを簡単に説明するしていきます。
6.2.1. 制限付きボルツマンマシン(RBM:Restricted Boltzmann Machine)
Deep Learningにおける 事前学習(Pre Training)法の一種で、良く名前を聞く自己符号化器(AutoEncoder)と双璧を為すモデルの1種で、主に分類、回帰、次元削減等に役立ちます。
これはシンプルな2層のニューラルネットで、最初の層は入力層、2つ目の層は隠れ層となります。
6.2.2. 積層オートエンコーダ(SAE:Stacked Auto Encoder)
オートエンコーダ(Auto Encoder)はNNの一種で、情報量を小さくした特徴表現を獲得するために出力を入力に近づけるよう学習するNNです。これをDL用に改良したのが積層オートエンコーダ(Stacked Auto Encoder)と呼ばれていますね。内容としては、
↓
中間層を1層作成した後出力層を取り除く
↓
中間層を入力層とし、更にもう1層積み上げる
↓
これを繰り返す
といった流れです。
6.3. 特微量とは
Deep Learningを理解する上でダントツに重要度が高いワードなので、とりあえず例を挙げてみます。
例えば、アパレルのお店を立ち上げる際に売り上げに関連しそうな要素は、
- 仕入れる服のテイスト
などなど、ざっとですが要素が沢山あります。これらの結果(=売上数)に影響を与えそうな要素を”特徴量”といいます。これらを以前の機械学習では人間が作成していたが、Deep Learningでは勝手に生成してくれます。
6.4. DLの主なアルゴリズム
ここで一部ですがアルゴリズムを簡単に説明します。
http://developers.gnavi.co.jp/entry/tensorflow-deeplearning-3 上記の事前学習と同じだが教師の有無で違う(下記は教師あり?)
これらのモデルはニューラルネットワークの中間層を多層にする手法
http://gagbot.net/machine-learning/ml4 ここからとりあえず流れ学ぶ
一部紹介します
6.4.1. LSTM(Long short-term memory)
RNN(Recurrent Neural Network)の拡張として1995年に登場した、時系列データ(sequential data)に対するモデル、あるいは構造(architecture)の1種で、RNNを実現するために考案されています。
こちらRNNとの比較画像です。
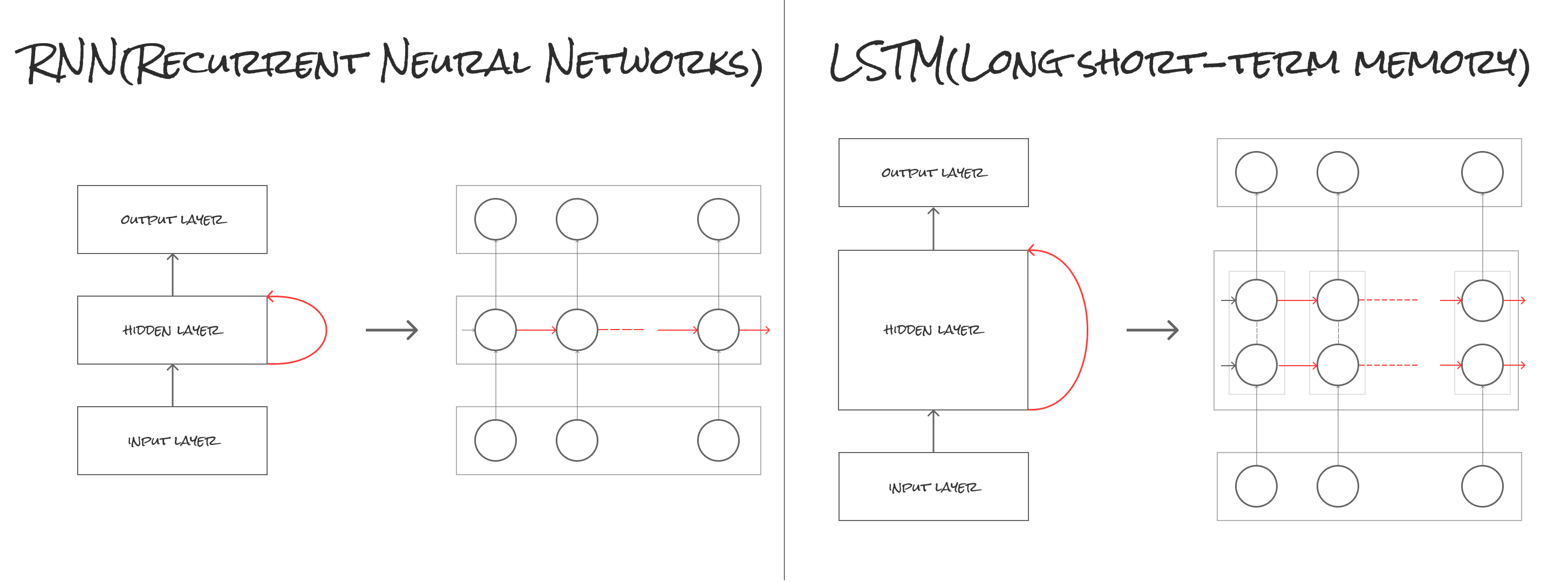
大きな特徴としては、 RNNの持つ勾配消失問題を解決することで長期の時系列(保持具合を調整、又は忘れる)を学習可能としました。上記画像でいうとLSTMが中間層においてRNNより1つニューロンが多い構造になっています。このニューロンが保持と時々忘れるといった役割を保っています(かなりざっくりですが)。
6.4.2. 敵対的生成ネットワーク(GAN:Generative Adversarial Network)
GANとは敵対的生成ネットワーク(Generative Adversarial Network)と呼ばれていて、Ian Goodfellowが考案したモデルとなります。
主な流れとして
↓
ジェネレーターは本物と同じような内容を作り出す
↓
一方でディスクリミネイターはレプリカか本物なのかを識別する役割を持つ
↓
レプリカを作る方は本物と近づけようとし、対して識別する方は確実に見分けられるよう互いに競い合う
のような感じですね。
次回のブログで以上について実装してみたいなと思います。
6.5. 活性化関数とは
入力信号の総和がどのように活性化するかを決定する役割を持ちます。これは、次の層に渡す値を整えるような役割を持ちます。
結論から言えば、ReLUは
max(0,x)
で表される非常に単純な関数で、
- それ以上ならば入力xxを通過
- 偏微分係数は、入力が0以下ならば0、それ以上ならば1となる
ここに関しては僕が少ししか理解していない為、DL実装する際は活性化関数をもっと理解しないといけないなと感じました....
7. Labellioでテスト
なんか動かしてみないと実感沸かないので、今回はLabellioを使用しDLを体験しました(画像専門ですが)。
7.1. 概要
Labellioとは、画像認識モデルを高速に作成(モデル数によりけり)出来るツールです。私のような初心者でも気軽に操作できます。
Dlを学習するにあたって私が感じたのは
- 学習アルゴリズムに与えるデータの準備
の2つを用意するのはかなり手間がかかるでは...と思いました。しかしLabellioを使用する際はその用意が必要がない為、誰でも簡単にDL体験が出来ます。
またLabellioの特徴として、
- Labellioが自動生成する画像認識モデルは、Caffeを組み込んだ画像認識アプリケーションで利用可能(今後いじってみたい)
のようですね。ちなみに2017年10月30日から有料プラン提供開始したみたいですね。では早速いじってみましょう(設定等の細かいことは公式のマニュアルを見れば分かるので省きます)。
7.2. 使用過程
今回は4つの画像を区別しようと思います
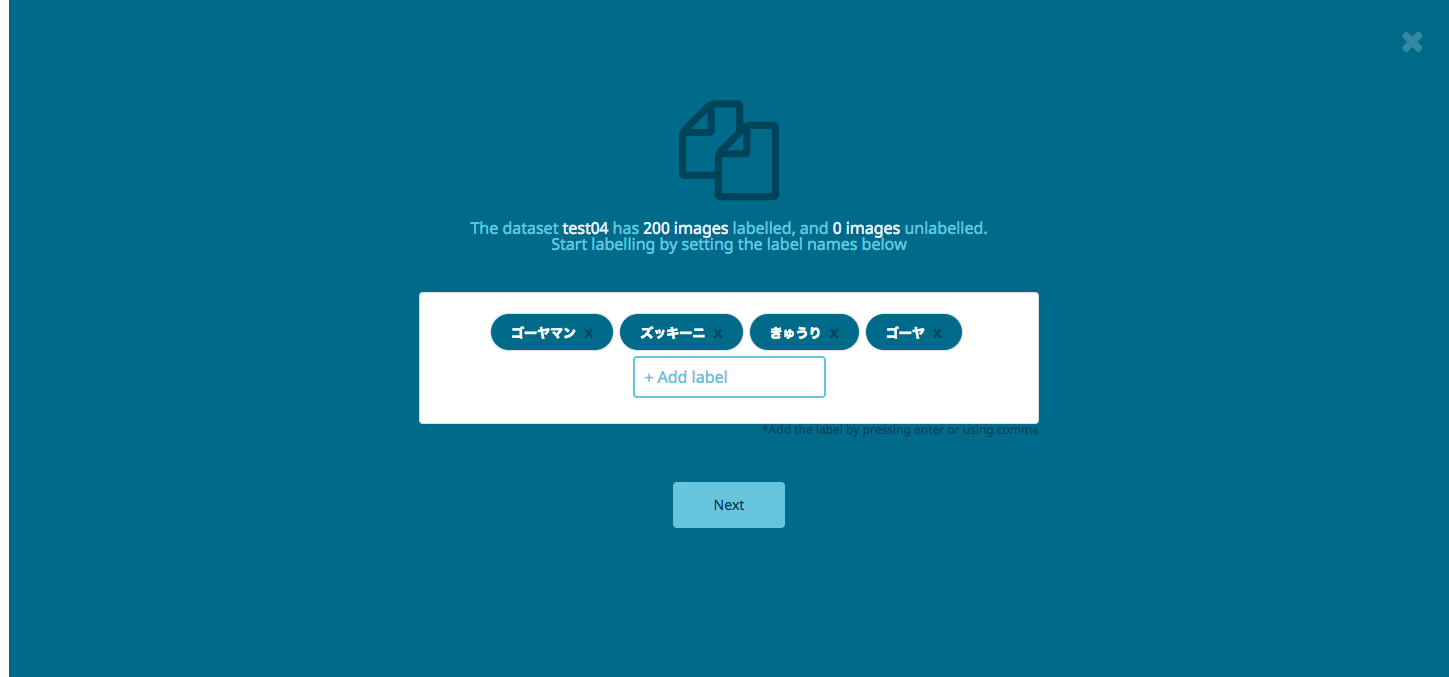
- ゴーヤマン
- きゅうり
- ズッキーニ
かなり分類機をいじめている気がしますが、これで試してみます。おそらく形が似ている為、色や形が少しでも変わると分類出来ないのではないか...?と疑問を抱いていますがやってみましょう。
一旦データを入れ込んだら現在の分類機の精度が大まかに確認出来ます。
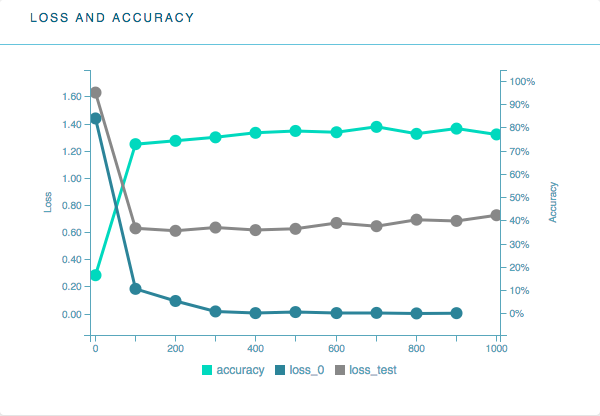
うーん、いまいちですね。本来lossが低くないといけないのですが、データでいじめてしまったので仕方がありません(=おそらく精度が低い)。とりあえず実験なのでこのまま進めてみましょう。
一体どこまでの精度を発揮してくれるのか、試していきます。
最初はゴーヤからいきます。

お、調子が良いですね。
続いてゴーヤマン。

かなり調子がいいですね。ここまではこの4つの中ではかなり見た目にパンチが効いた色と形なので、正確に分類できたと感じます。なので少し分類機をいじめてみましょう。続いて少し形が通常と違うきゅうり(太め)。

やはり少し形が変わると認識されませんね。続いて熟す前のゴーヤ(黄色)。

こちらも認識されませんね...。
7.3. 結果
精度はやはり低かったです。今回は人間でも間違えそうな識別を機械に任せてみましたが、案の定機械も色や形が変わるとまだまだ精度が低いことが分かりました。このツールは教師有無どちらも試せます。テストで5つくらい分類機を作成しましたが、やはり自分で画像を用意してラベルをつけるやり方(教師あり)だとかなり労力を使う&精度もかなり落ちるなと感じました(そもそも1人用意できる画像数なんて高がしれていますが)。
8. まとめ
最初にも述べましたが、やはり結論は下記の3つですね。
- 適時適応することが最も重要
- とりあえずAIという言葉はかなり広義で曖昧
今回はかなり簡潔に学習したことを説明しました。今後さらにDL周りのフレームワークやアルゴリズムが増えていくと思いますが、もっと基礎を固めないと...と痛いくらい感じました。次回はPython*TensorFlow実装に関して記事を書きたいと思います。長々とありがとうございました。
9. ベトナム・オフショアでのAI開発ならバイタリフィへご相談下さい
ベトナムへ進出されるならホーチミンで約9年、オフショア開発・アプリ開発を展開しているバイタリフィ・バイタリフィアアジアへお気軽にご相談ください。弊社ではAI関連の研究に力を入れて進めております。
ベトナムでのオフショア開発における『フロントエンド開発』や『アジャイル・スクラムでのサービス開発』も得意としております。またベトナム向けIT・WEBサービス/アプリの開発支援、ローカライズ、テストマーケティングといった進出支援に加えて、日本や他国向けのオフショア開発やアプリ開発も行っております。
