制作部のディレクター、モリヤです。
去る5月13日、東京ビッグサイトで行われた、AIエキスポに行ってきました。
弊社はわりと自由に、勉強会など外部の催しにも参加させてくれます(業務に影響を及ぼさない範囲で)。
.jpg)
私の一番の目当てはこれ。
早稲田大学理工学術院教授、尾形哲也先生の講演、
【深層予測学習によるAIとロボットの共進化と実世界応用】

かいつまんで説明すると、
国によって行われているムーンショット計画にも参加しているチームで、
…あ、私も不勉強で講演で初めて知ったので、ムーンショット計画を解説しますね。
『将来の社会課題を解決することで、人々の幸福の実現を目指す計画』
でして、9つの具体的な目標が立てられています。詳しくはこちらのリンクをどうぞ。
ムーンショット目標3の、
『2050年までに、AIとロボットの共進化により、自ら学習・行動し人と共生するロボットを実現』
する研究テーマのひとつ、
『一人に一台一生寄り添うスマートロボット』
が、今回の講演の尾形先生チームの所属プロジェクトです。
なので、身の回りを少し助けてくれる、日常的なロボットについての話だと思っていただければ。
では、本題に戻りましょう。
…かいつまんで説明すると、
ロボットをどのように学習させて、今、どのような成果が出ているかの興味深い報告となっていました。
◆ロボットの学習方法解説
内容を以下にまとめますね。私の捉え違い等ございましたら、ご指摘ください。
ロボットをどのように学習させ、目的の動きを達成するかという面において、方法は2つ。
1つめは、
画像、音声、自然言語による深層学習、すなわち機械学習です。
例えば、ロボットにネコを学習させたいとして、
ネコの写った写真を片っ端から、それはネコだと学習させていく。角度だったり、品種を変えたり、様々な写り方をするネコの写真をインプットさせることで、他のネコを見た時に、それはネコだと認識できるようにするのです。
ついでにネコがたくさん写っているMaiさんのブログはコチラ。
でもネコって三次元だから、少しでも写り方が違えば、写真は同じにはなって来ませんよね。どれだけ写真を撮っても可愛いからもっと撮りたい飼い主心、1つとして同じ写真はないのです。
ネコは三次元の生き物なのに、二次元で認識させるから膨大で学習が難しくなってしまう。
そして、別の写り方をしたネコは、最早ロボットにはネコだと分からないことがある。
この学習方法のデメリットは、学習すればほどほど良い正解率を導き出せることは間違いないのですが、学習すべきデータはどれだけで完璧になるかと言われると、100%になることはないわけです。
これ、チャットボットに通じますね。
AIはなんでも答えられるようでいて、実はインプットしていないことには答えられないので、想定外の質問に対する未学習は存在し、そこが、なんでも答えられると思っているユーザーの期待に沿えない側面もあるのです。
つまり、出力を間違える(チャットボットで言えば質問が用意されていない、または導線が不足)ことはどんなに学習しても起こり得る。
ではロボット開発において、どう対処したらいいのか?
人間の認知機能で考えると、
学習コストの低い順から高い順に並べると、
①知覚を変えることで予測を変える
②動作により感覚を変える
③学習により内部モデルを変える
3種類の学習方法が存在します。
どういうことかというと、
①人間ならば地球儀を『日本を自分側に向けて』いようが、『カナダを自分側に向けて』いようが、同じ地球儀であると認識できるのです。
致命的な誤差でなければ結構受け入れるという機能が、人間の脳には備わっているようです。
因みに、人間の発達曲線において、有名なピアジェの3つの山問題というのがありまして、7歳くらいまでの子供は重なり合う3つの山の、見る方向による見え方の差が分からないというもの。
親が名前で呼ぶから自分を名前で呼んでしまうのも、その一種でしょうね。
注:刺激の与え方を変えることで実験結果は変化するため信憑性は低いとする説もありますが、ここではざっくり、成長すると違いが分かるようになる、とお考えください。
小学生に実際に山を描かせた興味深い研究も見付けました。こっちがリアルな現状の気もしますね。
…であるからして、異なるものも同じと認識できる能力は、後天的に取得するようですね。
この能力を取得するところではなしに、頭の中で見方を変えるだけで認識完了なので、コストが低いわけです。
②は、ネコの例で言えばネコを触ることによって、それがネコだと分かること。
頭の中で認知を変えるのみよりはコストがかかりますが、触るだけで良いので、ある程度簡単にできます。
③が、1つめの方法にもあった、ネコの写真をひたすら見せて勉強する方法。テキストだけを詰め込む学習法です。
人間でも一番しんどいですよね。
①はロボットにどのように適用するのかというと難しいところですが、②であればさせることが可能で、それが実際に先生のチームでロボットを学習させている、2つめの方法です。
どういうことかというと、機械学習で与えたデータ以外の誤りについて、全部修正の必要はないのです。それではキリがない。
誤作動をどう扱うのか?そこが重要で、予測誤差最小化を目指していくための取り組みとなります。
チャットボットも、ユーザーの入力が何にも引っ掛からなかった時の回答は用意していますが、その発想はなかった…
◆新たな学習方法、深層予測学習
②の学習を深層予測学習と銘打ち、その方法は、
人間のテレオペレーションで物体(例えばタオル)を畳ませ、タオルが畳まれる時にはどのような見え方の変化があるのか、何度も繰り返し覚え込ませる。
すると、ロボット側で予測画像を持つようになり、新しいタオルを見せた時に、実際の画像ではなしに、ロボットがタオルはこれだと思っている画像が見えてきます。
その「現実と知覚を合わせた画像」は明晰ではありませんが、予測は完璧にできなくてよいのです。というより、できない。なぜなら世界はオープンだから。
タオルを学習させていると、本を見せてもタオルが出てきたりなどエラーはありますが、それはそれ。
触覚、力覚も予測の対象なので、総合して計算した時に、
台所で例えばスープや目玉焼き、グリーンピースの集団、野菜炒めなど、これらを扱う時におたまとフライ、どちらを使うかといった、日常的にあり得る判断基準を、ロボットも持てるようになるのです。
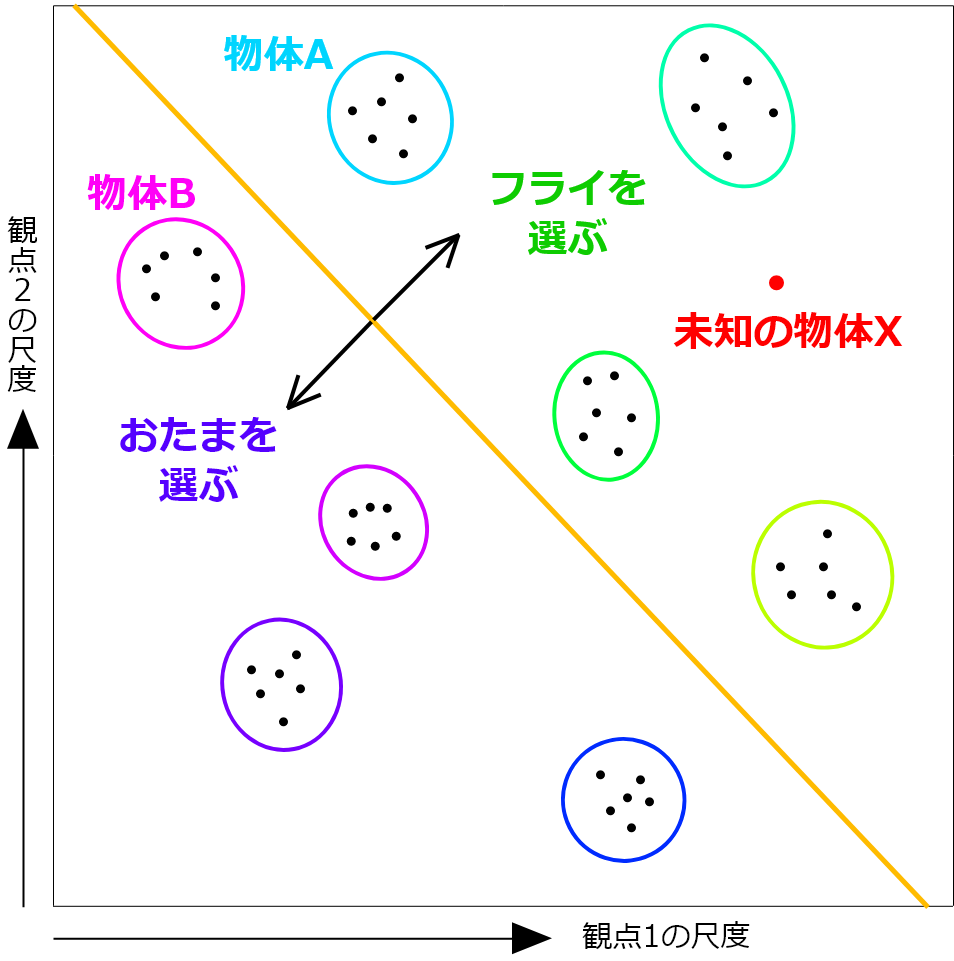
まず、種類Aの集団の幾つかの例を学習させ、物体Aにはフライを使うと教える。
次に、同様に物体Bの場合はおたまと学習させる。このパターンを数種類繰り返し、物体の特徴を(大きさと固さとか?)二軸で学習データを与えれば(ここうろ覚え)、未知の物体Xを与えた時に、フライとおたまのどちらを使えば良いのか、物体の類似性でどちらの道具を選ぶか予測ができるようになってくるのです。
少ない学習手数で、新しいことにも対応させ得る、それが、深層予測学習。
チャットボットもこういうことを考えられないか、考えてみようと思わせられました。
ひも結び、ドアの学習などもお話はありましたが、ここでは割愛しますね。
昔のロボットの研究は、今まで、直ぐ作れそう、使えそうなものを研究してきたのが、今は、直ぐに役に立たなくても自然な(人間に近い)ものを研究しているそう。
同じバイオの研究室でも、企業と大学の研究の違いについて、企業では応用研究や開発研究(明確に使用の目的のあるものを研究する)に対し、大学では基礎研究(いつ何に役立つか分からないが研究する)を行うようなものですね。工学は理学と比べ、最初から役に立つものを研究すると聞いたこともありましたが、工学の世界も直ぐ直ぐの研究ではなくなって来ているのかな。
元々私が理学研究科出身ということもあり、大変興味深くお話を伺いました。ハードな媒体のプログラミングも面白そうですね。
◆余談
講演を聞いたあとは、会場を見回って刺激を受けてきました。

弊社のFirstContactのブースもがんばっていました。用意したチラシ500部以上がなくなったとのこと。
3日目の昼に行った時にはもう売り切れ。嬉しい誤算ですね!

グループのアイスマイリーのブースにもご挨拶してきました。活気があって、スタッフの皆さんも楽しそうに応対されていました。とても賑わっていたので、集客のコツを教えていただきたいものです。
お話ししたSさん、ありがとうございました!私の準備不足で名刺探し出せなくてすみません!
これからもよろしくお願いします。
ところで、当日は雨が降っていましたが、東京ビッグサイトには駅からずっと屋根があるので、傘はいらなかった…

これからビジネスで東京ビッグサイトに行く予定のある方は、お気をつけを。
お相手は私、モリヤでした。
守屋のおすすめ日常ブログ【ジェンダーギャップ指数2022と我が家の事情】